Situatie
Când vine vorba de a face cereri web, sincronizarea este crucială. Nimănui nu-i place să aştepte la nesfârşit ca o pagină web să se încarce sau un server să răspundă. Dacă utilizați curl pentru a prelua date de pe web, veți fi încântați să aflați că există modalități de a limita timpul necesar solicitărilor dvs.
Iată cum puteți limita timpul de solicitare curl pentru a vă asigura că păstrați controlul asupra operațiunilor de preluare a datelor.
Solutie
Pasi de urmat
Method 1: Using the –max-time Option
În timp ce rulați comanda curl, puteți specifica opțiunea -m sau –max-time pentru a seta o limită strictă de timp pentru cerere. Această opțiune vă permite să specificați timpul maxim, în secunde, pe care sunteți dispus să lăsați comanda să dureze înainte de a ieși cu un cod de eroare de timeout (28):
curl –max-timе [sеconds] [URL]
Puteți defini maximul cu precizie zecimală, unde 0,3 înseamnă 300 de milisecunde, 5,46 este egal cu 5.460 de milisecunde și 20 înseamnă 20 de secunde.
De exemplu: curl -o test.md –max-time 30 https://github.com/test/file1

Această comandă trimite o solicitare la adresa URL GitHub furnizată. Acesta va salva datele de răspuns ca test.md și va termina într-un timp maxim de 30 de secunde.
Metoda 2: Utilizarea opțiunii –connect-timeout
Pentru a controla timpul petrecut curl încercând să se conecteze la o gazdă, utilizați opțiunea –connect-timeout. Aceasta stabilește o limită de timp maximă pentru curl pentru a finaliza pașii de conectare, inclusiv căutarea DNS și strângerile de mână TCP, TLS sau QUIC ulterioare. Dacă curl nu poate stabili o conexiune în intervalul de timp pe care îl specificați, acesta va ieși cu un cod de eroare de timeout (28):
curl –connect-timeout [seconds] [URL]
De exemplu:
curl -o test.md –connect-time 20 https://github.com/test/file
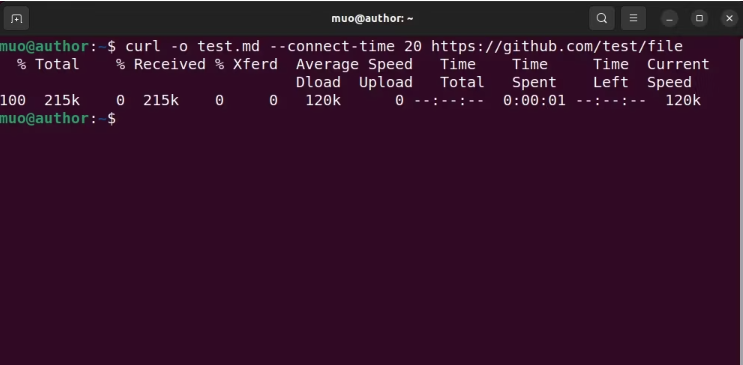
Aici, comanda curl preia fișierul specificat în URL, îl salvează ca test.md și impune o limită de 20 de secunde pentru stabilirea conexiunii cu serverul.
Leave A Comment?