Situatie
Solutie
What Is the head Command on Linux?
Linux has multiple commands to display file contents. The most popular and frequently used are cat, less, and view commands. However, these commands are more useful for displaying large portions of files. If you only need to show a specific number of lines of a file, the head command is there for you.
The head command does the opposite of what the tail command does. It shows the starting content of a file, while the tail command prints the ending lines of a file. By default, head displays the first 10 lines. If you want to print more or less than 10 lines, just use the -n option. Similarly, the -c option with the head command can restrict the output to a particular byte number.
The head command can analyze logs and other text files that are subject to vary over time. You can use the head command in conjunction with other commands for selective, real-time monitoring. The head command’s syntax is easy to understand and is similar to other Linux commands:
head [OPTION]... [FILE]...
The head command can take one or multiple files as inputs. It also accepts some options that modify its behavior and output. If no file is specified, the head command reads from the standard input.
To check the version of the head command, use:
head --version
Similarly, type the below command to output the head command help menu:
head --help
head Command Options
You can use various options with the head command on Linux. Each option has a concise and extended form, to use with basic syntax. It controls how much data the head command prints to the normal output. For example, it allows you to decide whether to include the header in the file output or not.
The following table contains the list of options available for the head command:
| Option | Description |
|---|---|
-n or --lines |
Defines the number of lines to display from the beginning. |
-c or --bytes |
Shows the specified number of bytes from the start. |
-v or --verbose |
Prints each file name along with the file contents. This is useful when displaying multiple files at once. |
-q or --quiet |
Suppresses the printing of file names before displaying their contents. This is useful when displaying only one file or when piping the output to another command. |
-z or --zero-terminated |
Replace the newline character with NULL at the end of each line. |
Before moving to the demonstration of the head command, let’s first look at the content of the sample file. Use the cat command followed by the filename to get all the data of the sample file.
cat example.txt
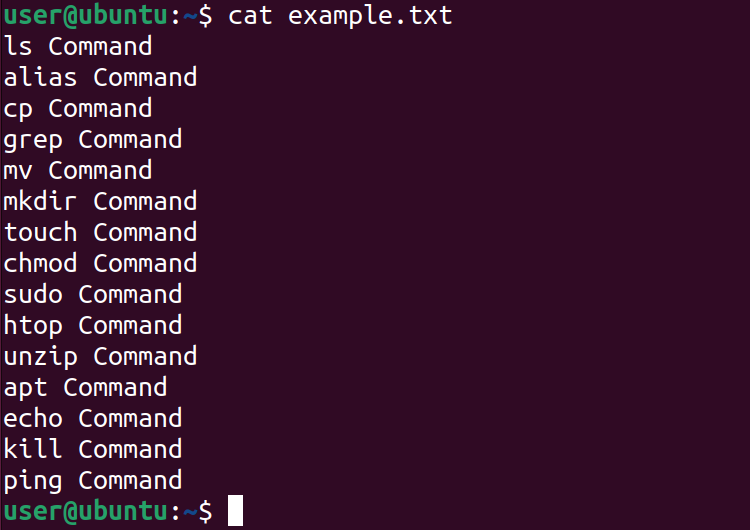
This example file contains 15 lines of text.
Now, let’s print the content of the example.txt file using the head command. The head command, without any options, will print the first 10 lines of the file.
head example.txt

Getting a Specific Number of Lines
To display a certain number of lines using the head command, add the -n (--lines) option followed by the file name.
To display the first four lines of example.txt, run:
head -n 4 example.txt

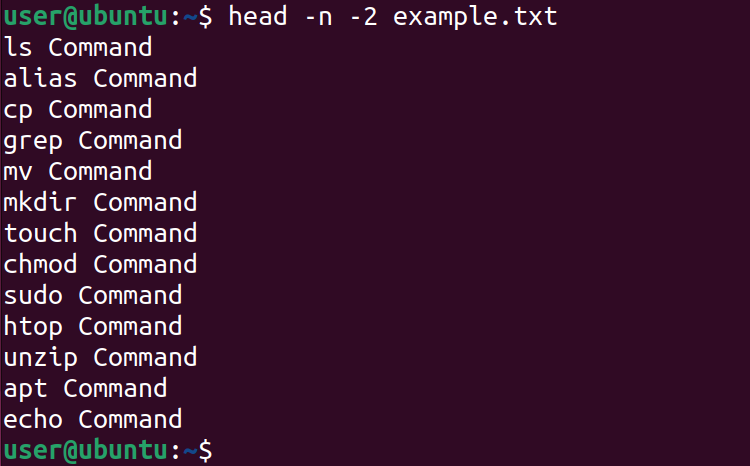
Similarly, a negative number can also be specified with the -n option. This will skip the last N lines of a file. This is helpful when you want to skip some lines at the end of a file.
For example, to skip the last two lines of the example.txt file, run:
head -n -2 example.txt
Pulling Specific Number of Bytes Using head
Another use case for the head command is to get a certain number of bytes from the start of a file. You can do this by using the -c (--bytes) option followed by a digit.
Consider you have the same file example.txt, and it contains 15 lines of text. To get the first 20 bytes, run:
head -c 20 example.txt

As the example.txt file contains ASCII characters, each of the characters including the space and a newline will take one byte.
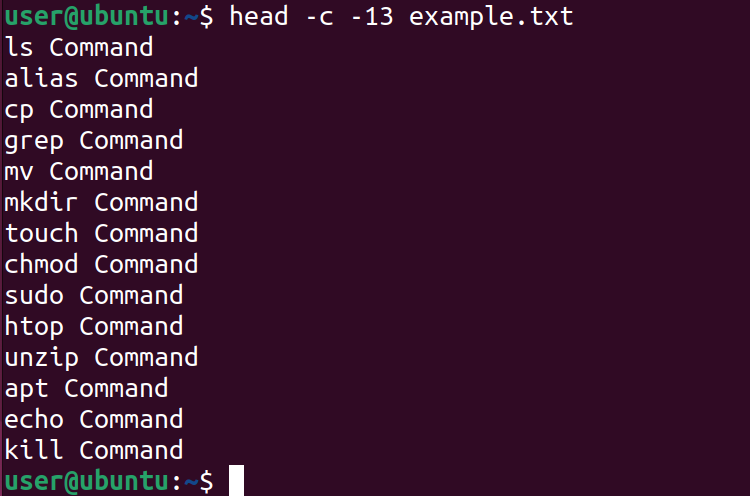
A negative number can also be defined with the -c option. This will display all bytes of a file, except the last N bytes. To display all the bytes in example.txt, except the last 13 bytes, run:
head -c -13 example.txt
Viewing Specific Characters in a File
Sometimes, you need to see a certain part of a file, rather than the entire file contents. Let’s say you have a file with multiple lines of contents, and you want to see the first or last characters of each line. For this, you have to pipe the head command with other text processing commands like cut, awk, or sed.
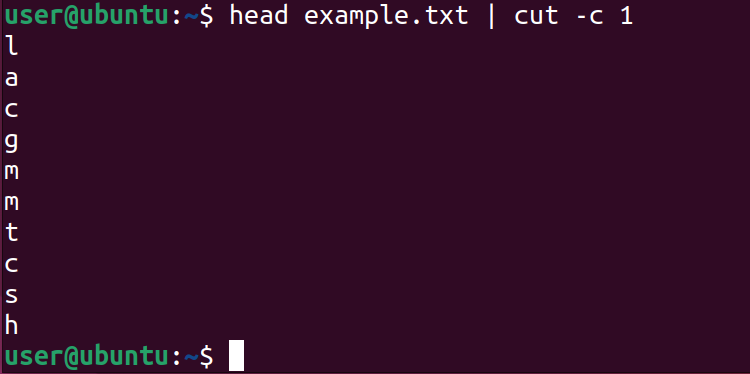
For example, to retrieve the first letter of each line of example.txt, use the cut command with the -c option followed by character position. By default, you will get the starting character of the first 10 lines, unless you specify the number of output lines.
head example.txt | cut -c 1
To see the last word of each line of example.txt, use the awk command with the {print $NF} pattern. Use the pipe operator (|) to pipe both head and awk commands. In this way, the output of the head command will serve as input to the awk command.
When you use {print $NF}, it tells awk to print the value of the last field for each line in the input. By using $NF, you don’t need to know in advance how many fields each line has; awk automatically handles it for you and extracts the last field.
head example.txt | awk '{print $NF}'

Seeing the Header/File Name With head
By default, when the head command is used with a single file, it does not print the file name. However, it can display the file name when used with multiple files. Use the -v option to get the file name along with its content. This option prints a header with the filename of the specified file.
head -v example.txt

Displaying Contents of Multiple Files With head
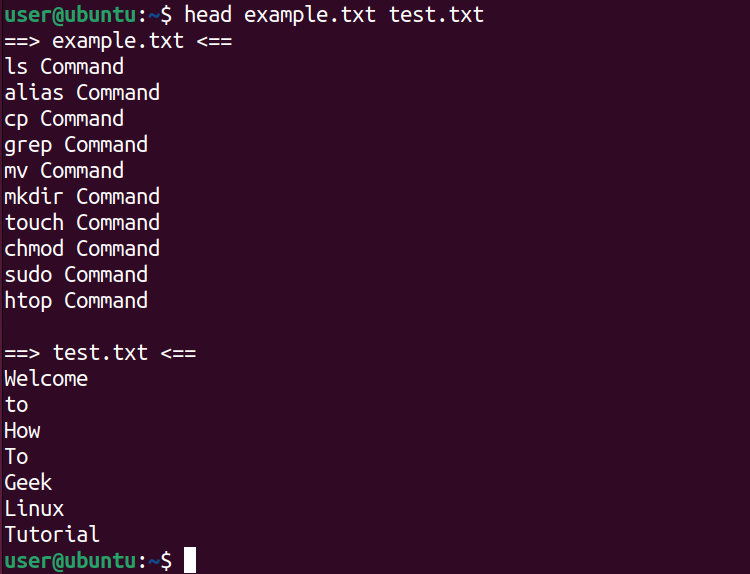
The head command can also take multiple file names as arguments and display their contents in order. Let’s take two files called example.txt and test.txt that contain multiple lines of content. Now, the head command will display both file names along with their content.
head example.txt test.txt
You can use the head command with the -q option to view the content of multiple files without displaying their names.
head -q example.txt test.txt

Using head With Other Commands
The head command can also be used with other commands to perform various tasks. You can use it with tail, more, wc, and grep commands.
You can pipe the head command with grep to give you all the lines that contain the specified pattern.
head example.txt | grep ch

The above syntax displays all lines in the example.txt file that contain “ch”.
You can also pipe the head command with the wc command. Both these commands will output the count of total lines, words, and bytes in the file.
To get the number of lines, words, and bytes in the example.txt file, run:
head example.txt | wc

You can use the head and tail commands together with the pipe symbol to display a specific range of lines from a file. The head command shows the starting lines of a file, while the tail command prints the ending lines of a file.
Consider the example.txt file that contains 15 lines. To display the contents between 5th and 11th lines, run:
head -n 10 example.txt | tail -n 5
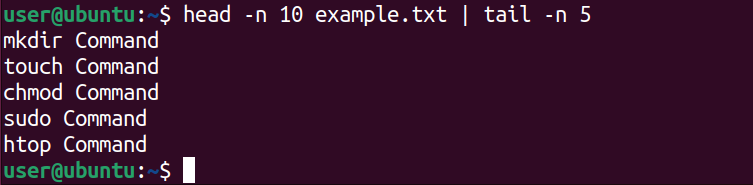
This command works by first using the head -n 10 command to show the first 10 lines of the file. After that, it will pipe the output to the tail -n 5 command. The tail command will give us the final output of entities that are between the 5th and 11th lines.
Want to Display Line Endings With head?
The head command, as its name implies, is primarily concerned with the initial lines of a file. Conversely, the tail command serves the purpose of displaying the concluding lines of a text file. Usually, new data is added to the end of a file, so the tail command is a quick and easy way to see the most recent additions to a file. It can also monitor a file and display each new text entry to that file as they occur.
Just like the head command, you can also use tail to monitor multiple files or count the number of bytes. It can also check a specific pattern or text inclusion in the text file. This makes it a great tool to monitor log files.
Leave A Comment?